UML (Unified Modeling Language) is an Object Management Group (OMG) standard which is a successor to many of the Object Oriented methods developed in the 80s and 90s. The idea of using UML to model XML document is not new. Good stuff has already been published on the subject (see for instance the book "Modeling XML applications with UML" (Addison Wesley, 2001) by David Carlson or his articles on XML.com).
There are two different levels at which UML and XML can be mapped.
UML can be used to model the structure of XML documents directly. XML schemas can be generated for the purpose of validating the documents but they are provided as a convenience for application developers. UML doesn't worry about schema details. Their style and modularity are not their most important features. The algorithm for producing these schemas is focused on expressing validation rules which make the XML data match the UML diagram as closely as possible.
UML can be used to model an XML schema. The UML diagram is a higher level view of the schema and the schema by itself is the main delivery. The UML diagram needs to be able to control exactly how each schema structure is described. Specific stereotypes and parameters are often added to customize the level of control.
One of the points which appears clearly in all the work related to this topic is that it is quite easy to map UML objects into XML or to use UML to describe classes of instance documents. The most difficult issue when doing so is that UML operates on graphs while XML is a tree structure. Some links need to be either removed or serialized using techniques to make the mapping happen cleanly (you can use XLink, but it isn't built into XML 1.0). Except for this issue, the relationship between UML and XML is quite natural in both directions: UML provides a simple language to model XML documents and XML provides a natural serialization syntax for UML objects.
Another point concerning XML and UML is that it's not that simple to generate DTDs and W3C XML Schemas from UML. When generating DTDs or W3C XML Schemas from UML you have to cope with the restrictions of these languages, notably those related to unordered content models Unordered content models are a natural fit for UML, in which the attributes of a class are unordered. The limitations of DTDs and W3C XML Schemas create problems when UML attributes are serialized as XML elements.
The issue when modeling W3C XML Schemas in UML is that the model needs to describe the XML instances and the schema itself. This is where all the complexity of W3C XML Schema enters the UML world. While there is a good overlap between UML and XML, the overlap is not so good between XML and W3C XML Schema. W3C XML Schema has in some ways enriched XML with its own expectations, and its expecations don't match those of UML. Figure�4 shows how the overlaps work and don't work:
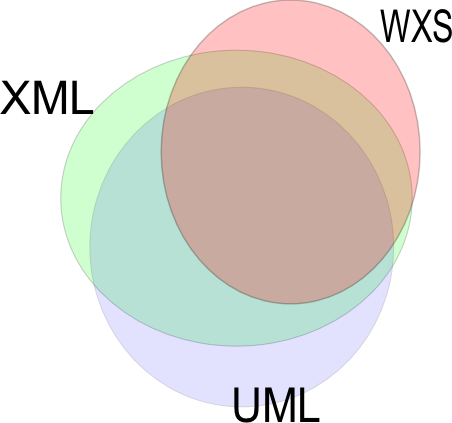
With RELAX NG, on the contrary, the overlap between XML and the schema language is nearly perfect: RELAX NG can describe almost any XML structure. As it has no notion of a Post Schema Validation Infoset (PSVI), RELAX NG doesn't want to add anything to XML. As a result, the overlap between UML, XML, and RELAX NG is almost as big as the overlap between UML and XML, as shown in Figure�5:

Designed with a UML editor such as ArgoUML, our library could be pictured as the model shown in Figure 14-6:
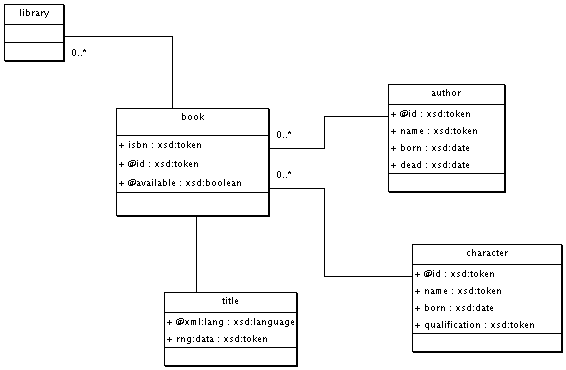
This example uses conventions which may look natural but are far from being official. For instance, I have prefixed attribute names with @, an idea borrowed from Will Provost's work on XML.com. Also, to model the title element with its text node and attribute, I have used the name rng:data to identify its text content as a UML attribute.
ArgoUML saves its documents using the XML Metadada Interchange (XMI) format defined by the Object Management Group (OMG). (You can find more information about XMI at http://www.omg.org/technology/xml/.) XMI is verbose. The XMI document generated by ArgoUML for this diagram is more than 800 lines long. I won't include it here, but there is no major difficulty in generating a schema from this document with unordered content models, such as:
<?xml version="1.0" encoding="utf-8"?>
<grammar xmlns="http://relaxng.org/ns/structure/1.0"
datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
<element name="library">
<interleave>
<zeroOrMore>
<element name="book">
<interleave>
<element name="isbn">
<data type="token"/>
</element>
<attribute name="id">
<data type="token"/>
</attribute>
<attribute name="available">
<data type="boolean"/>
</attribute>
<zeroOrMore>
<element name="author">
<interleave>
<attribute name="id">Foundation.Data_Types.Multiplicity
<data type="token"/>
</attribute>
<element name="name">
<data type="token"/>
</element>
<element name="born">
<data type="date"/>
</element>
<element name="died">
<data type="date"/>
</element>
</interleave>Foundation.Data_Types.Multiplicity
</element>
</zeroOrMore>
<zeroOrMore>Foundation.Data_Types.Multiplicity
<element name="character">
<interleave>
<attribute name="id">
<data type="token"/>
</attribute>
<element name="name">
<data type="token"/>
</element>
<element name="born">
<data type="date"/>
</element>
<element name="qualification">
<data type="token"/>
</element>
</interleave>
</element>
</zeroOrMore>
<element name="title">
<attribute name="xml:lang">
<data type="language"/>
</attribute>
<data type="token"/>
</element>
</interleave>
</element>
</zeroOrMore>
</interleave>
</element>
</start>
</grammar> |
Or, after conversion into the compact syntax with Trang:
start =
element library {
element book {
element isbn { xsd:token }
& attribute id { xsd:token }
& attribute available { xsd:boolean }
& element author {
attribute id { xsd:token }
& element name { xsd:token }
& element born { xsd:date }
& element died { xsd:date }
}*
& element character {
attribute id { xsd:token }
& element name { xsd:token }
& element born { xsd:date }
& element qualification { xsd:token }
}*
& element title {
attribute xml:lang { xsd:language },
xsd:token
}
}*
} |
The only trouble I've had with RELAX NG itself comes out of one of the few restrictions of RELAX NG, which was mentioned in Chapter 7: Constraining Text Values. Data patterns cannot be interleaved. When generating this schema one must be careful to treat complex type simple content models (i.e. elements such as the title element which accepts attributes and text nodes but no children elements) as an exception. This straight translation is, of course, impossible with W3C XML Schema because of the cardinality of the character and author sub elements. Containers would need to be added to fit into the limitations of that language.
Note that we have generated a Russian doll design. Depending on the strategy used in the translation, we could have generated other designs as well.